
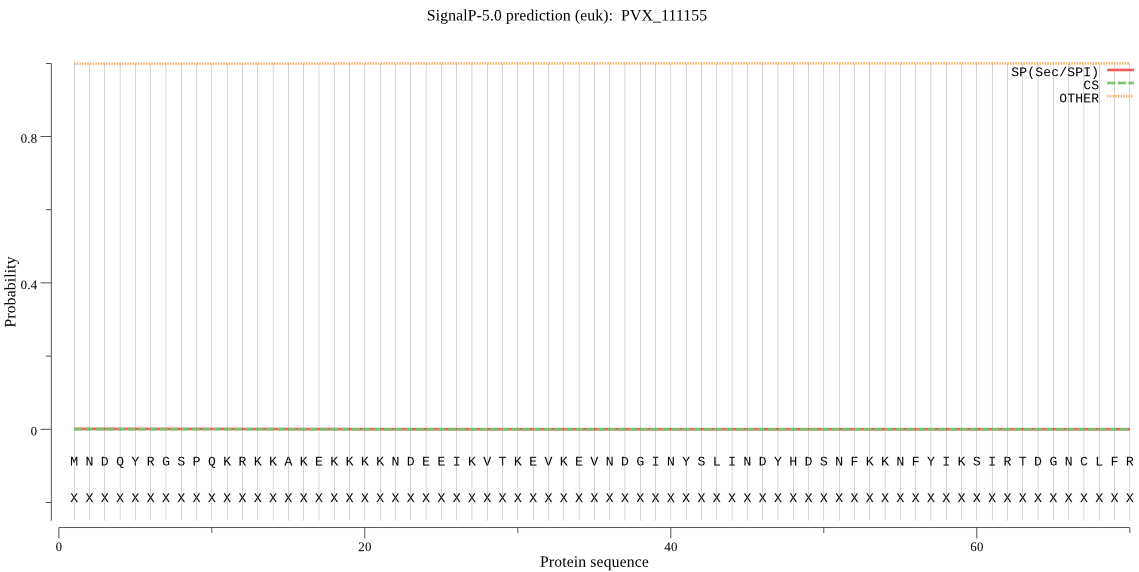
| _ID | Prediction | OTHER | SP | mTP | CS_Position | |
|---|---|---|---|---|---|---|
| PVX_111155 | OTHER | 0.999957 | 0.000001 | 0.000042 |
MNDQYRGSPQKRKKAKEKKKKNDEEIKVTKEVKEVNDGINYSLINDYHDSNFKKNFYIKS IRTDGNCLFRAVSDQLYNSEDNYKEIRKLVVDHLLRNEEKYQHFIEYDESYKSYIERISL DGTWGGQLELQAVGELFTVNILIYQENGCILEIKNHSDDKKCIQLHYASSEHYNSVRFKN RALENQLKSIVELREILNNKDDNESTKTFYETTDNELTEDNEDDLSDHTGNENKNVGEWV DEREFTLNSSVEEDYLQYDYPQENNRNNIFSLSDDETEPCSFDILQNIHNGIKRKGVRSR SMPTINERFLYFFAKNQVSESMDSDSTIDVLNEKKGFERRKPKKNENRKLNFLKYNYIGQ RPDDLLSECVSAAGKSETAVGKSQSAAEATTAVGAAPLLGEENKTIRICYNKTFYKYLCM SKMVEVEDRQRGKAADLVGGHYECGSGGGQACRIAAAAKAAPGKATPPKGEAANDAAKEA AKGAAGKSHRRSEANLGEPPTPLKHLNSAGRQGYISNYELENNFSRAKKKEFDDFLNLYS EKISYSRNSFCKSMSTNDCKSSHAEGVADGMAAPTSEQATSDYVNYEYARSLSLNKTSSS NEEVTAPSFCFDKDSISFELRPDVYGKGVERSDLATEGDARNKCVAHQNEEGKKIFCNLT RKSQDIFDIIIDEEYVLSMDSNLLCSHIGNKHVGRGSWHKKRGNSQQEEVLSQMRGRGGG KVSYPVVSPCVLNSRASFSGSRAPRGGKTSQIAAKLGGDHDRAGRGPNCRIRRRNHEGEG SGEGSGEGSGDTSAHSHTDASARSSTDRSGNSHTEISNHPRRDPPRRGGMNARDLFLKKK YLNKKFINMFSKDVHSKGLFHFLNADFLLSGDKIKYIIPFLFNSKQMNIFKDNLNRKEIH FYEYVTFSFNLDKQKLRKKIECSKVLNEEFLIKEKHKYSKFTRGGDGKSACSLRRGLENR VKIISI
| ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | ID | Site | Peptide | Score | Method | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PVX_111155 | 271 S | NNIFSLSDD | 0.992 | unsp | PVX_111155 | 271 S | NNIFSLSDD | 0.992 | unsp | PVX_111155 | 271 S | NNIFSLSDD | 0.992 | unsp | PVX_111155 | 326 S | MDSDSTIDV | 0.991 | unsp | PVX_111155 | 488 S | AAGKSHRRS | 0.993 | unsp | PVX_111155 | 492 S | SHRRSEANL | 0.991 | unsp | PVX_111155 | 516 S | QGYISNYEL | 0.991 | unsp | PVX_111155 | 705 S | KRGNSQQEE | 0.996 | unsp | PVX_111155 | 737 S | NSRASFSGS | 0.993 | unsp | PVX_111155 | 796 S | TSAHSHTDA | 0.998 | unsp | PVX_111155 | 804 S | ASARSSTDR | 0.993 | unsp | PVX_111155 | 805 S | SARSSTDRS | 0.995 | unsp | PVX_111155 | 812 S | RSGNSHTEI | 0.991 | unsp | PVX_111155 | 113 S | ESYKSYIER | 0.992 | unsp | PVX_111155 | 250 S | TLNSSVEED | 0.995 | unsp |